Code
library(tidyverse)
library(tidytext)
library(tm)
library(e1071)
library(topicmodels)
library(stringi)In this practical, we are going to use the following packages to create document-term matrices on BBC news data set and apply LDA topic modeling.
library(tidyverse)
library(tidytext)
library(tm)
library(e1071)
library(topicmodels)
library(stringi)The data set used in this practical is the BBC News data set. You can use the provided “news_dataset.rda” for this purpose. The raw data set can also be downloaded from here.
This data set consists of 2225 documents from the BBC news website corresponding to stories in five topical areas from 2004 to 2005. These areas are:
1. Use the code below to load the data set and inspect its first rows.
load("data/news_dataset.rda")
head(df_final)
## File_Name
## 1 001.txt
## 2 002.txt
## 3 003.txt
## 4 004.txt
## 5 005.txt
## 6 006.txt
## Content
## 1 Ad sales boost Time Warner profit\n\nQuarterly profits at US media giant TimeWarner jumped 76% to $1.13bn (£600m) for the three months to December, from $639m year-earlier.\n\nThe firm, which is now one of the biggest investors in Google, benefited from sales of high-speed internet connections and higher advert sales. TimeWarner said fourth quarter sales rose 2% to $11.1bn from $10.9bn. Its profits were buoyed by one-off gains which offset a profit dip at Warner Bros, and less users for AOL.\n\nTime Warner said on Friday that it now owns 8% of search-engine Google. But its own internet business, AOL, had has mixed fortunes. It lost 464,000 subscribers in the fourth quarter profits were lower than in the preceding three quarters. However, the company said AOL's underlying profit before exceptional items rose 8% on the back of stronger internet advertising revenues. It hopes to increase subscribers by offering the online service free to TimeWarner internet customers and will try to sign up AOL's existing customers for high-speed broadband. TimeWarner also has to restate 2000 and 2003 results following a probe by the US Securities Exchange Commission (SEC), which is close to concluding.\n\nTime Warner's fourth quarter profits were slightly better than analysts' expectations. But its film division saw profits slump 27% to $284m, helped by box-office flops Alexander and Catwoman, a sharp contrast to year-earlier, when the third and final film in the Lord of the Rings trilogy boosted results. For the full-year, TimeWarner posted a profit of $3.36bn, up 27% from its 2003 performance, while revenues grew 6.4% to $42.09bn. "Our financial performance was strong, meeting or exceeding all of our full-year objectives and greatly enhancing our flexibility," chairman and chief executive Richard Parsons said. For 2005, TimeWarner is projecting operating earnings growth of around 5%, and also expects higher revenue and wider profit margins.\n\nTimeWarner is to restate its accounts as part of efforts to resolve an inquiry into AOL by US market regulators. It has already offered to pay $300m to settle charges, in a deal that is under review by the SEC. The company said it was unable to estimate the amount it needed to set aside for legal reserves, which it previously set at $500m. It intends to adjust the way it accounts for a deal with German music publisher Bertelsmann's purchase of a stake in AOL Europe, which it had reported as advertising revenue. It will now book the sale of its stake in AOL Europe as a loss on the value of that stake.
## 2 Dollar gains on Greenspan speech\n\nThe dollar has hit its highest level against the euro in almost three months after the Federal Reserve head said the US trade deficit is set to stabilise.\n\nAnd Alan Greenspan highlighted the US government's willingness to curb spending and rising household savings as factors which may help to reduce it. In late trading in New York, the dollar reached $1.2871 against the euro, from $1.2974 on Thursday. Market concerns about the deficit has hit the greenback in recent months. On Friday, Federal Reserve chairman Mr Greenspan's speech in London ahead of the meeting of G7 finance ministers sent the dollar higher after it had earlier tumbled on the back of worse-than-expected US jobs data. "I think the chairman's taking a much more sanguine view on the current account deficit than he's taken for some time," said Robert Sinche, head of currency strategy at Bank of America in New York. "He's taking a longer-term view, laying out a set of conditions under which the current account deficit can improve this year and next."\n\nWorries about the deficit concerns about China do, however, remain. China's currency remains pegged to the dollar and the US currency's sharp falls in recent months have therefore made Chinese export prices highly competitive. But calls for a shift in Beijing's policy have fallen on deaf ears, despite recent comments in a major Chinese newspaper that the "time is ripe" for a loosening of the peg. The G7 meeting is thought unlikely to produce any meaningful movement in Chinese policy. In the meantime, the US Federal Reserve's decision on 2 February to boost interest rates by a quarter of a point - the sixth such move in as many months - has opened up a differential with European rates. The half-point window, some believe, could be enough to keep US assets looking more attractive, and could help prop up the dollar. The recent falls have partly been the result of big budget deficits, as well as the US's yawning current account gap, both of which need to be funded by the buying of US bonds and assets by foreign firms and governments. The White House will announce its budget on Monday, and many commentators believe the deficit will remain at close to half a trillion dollars.
## 3 Yukos unit buyer faces loan claim\n\nThe owners of embattled Russian oil giant Yukos are to ask the buyer of its former production unit to pay back a $900m (£479m) loan.\n\nState-owned Rosneft bought the Yugansk unit for $9.3bn in a sale forced by Russia to part settle a $27.5bn tax claim against Yukos. Yukos' owner Menatep Group says it will ask Rosneft to repay a loan that Yugansk had secured on its assets. Rosneft already faces a similar $540m repayment demand from foreign banks. Legal experts said Rosneft's purchase of Yugansk would include such obligations. "The pledged assets are with Rosneft, so it will have to pay real money to the creditors to avoid seizure of Yugansk assets," said Moscow-based US lawyer Jamie Firestone, who is not connected to the case. Menatep Group's managing director Tim Osborne told the Reuters news agency: "If they default, we will fight them where the rule of law exists under the international arbitration clauses of the credit."\n\nRosneft officials were unavailable for comment. But the company has said it intends to take action against Menatep to recover some of the tax claims and debts owed by Yugansk. Yukos had filed for bankruptcy protection in a US court in an attempt to prevent the forced sale of its main production arm. The sale went ahead in December and Yugansk was sold to a little-known shell company which in turn was bought by Rosneft. Yukos claims its downfall was punishment for the political ambitions of its founder Mikhail Khodorkovsky and has vowed to sue any participant in the sale.
## 4 High fuel prices hit BA's profits\n\nBritish Airways has blamed high fuel prices for a 40% drop in profits.\n\nReporting its results for the three months to 31 December 2004, the airline made a pre-tax profit of £75m ($141m) compared with £125m a year earlier. Rod Eddington, BA's chief executive, said the results were "respectable" in a third quarter when fuel costs rose by £106m or 47.3%. BA's profits were still better than market expectation of £59m, and it expects a rise in full-year revenues.\n\nTo help offset the increased price of aviation fuel, BA last year introduced a fuel surcharge for passengers.\n\nIn October, it increased this from £6 to £10 one-way for all long-haul flights, while the short-haul surcharge was raised from £2.50 to £4 a leg. Yet aviation analyst Mike Powell of Dresdner Kleinwort Wasserstein says BA's estimated annual surcharge revenues - £160m - will still be way short of its additional fuel costs - a predicted extra £250m. Turnover for the quarter was up 4.3% to £1.97bn, further benefiting from a rise in cargo revenue. Looking ahead to its full year results to March 2005, BA warned that yields - average revenues per passenger - were expected to decline as it continues to lower prices in the face of competition from low-cost carriers. However, it said sales would be better than previously forecast. "For the year to March 2005, the total revenue outlook is slightly better than previous guidance with a 3% to 3.5% improvement anticipated," BA chairman Martin Broughton said. BA had previously forecast a 2% to 3% rise in full-year revenue.\n\nIt also reported on Friday that passenger numbers rose 8.1% in January. Aviation analyst Nick Van den Brul of BNP Paribas described BA's latest quarterly results as "pretty modest". "It is quite good on the revenue side and it shows the impact of fuel surcharges and a positive cargo development, however, operating margins down and cost impact of fuel are very strong," he said. Since the 11 September 2001 attacks in the United States, BA has cut 13,000 jobs as part of a major cost-cutting drive. "Our focus remains on reducing controllable costs and debt whilst continuing to invest in our products," Mr Eddington said. "For example, we have taken delivery of six Airbus A321 aircraft and next month we will start further improvements to our Club World flat beds." BA's shares closed up four pence at 274.5 pence.
## 5 Pernod takeover talk lifts Domecq\n\nShares in UK drinks and food firm Allied Domecq have risen on speculation that it could be the target of a takeover by France's Pernod Ricard.\n\nReports in the Wall Street Journal and the Financial Times suggested that the French spirits firm is considering a bid, but has yet to contact its target. Allied Domecq shares in London rose 4% by 1200 GMT, while Pernod shares in Paris slipped 1.2%. Pernod said it was seeking acquisitions but refused to comment on specifics.\n\nPernod's last major purchase was a third of US giant Seagram in 2000, the move which propelled it into the global top three of drinks firms. The other two-thirds of Seagram was bought by market leader Diageo. In terms of market value, Pernod - at 7.5bn euros ($9.7bn) - is about 9% smaller than Allied Domecq, which has a capitalisation of £5.7bn ($10.7bn; 8.2bn euros). Last year Pernod tried to buy Glenmorangie, one of Scotland's premier whisky firms, but lost out to luxury goods firm LVMH. Pernod is home to brands including Chivas Regal Scotch whisky, Havana Club rum and Jacob's Creek wine. Allied Domecq's big names include Malibu rum, Courvoisier brandy, Stolichnaya vodka and Ballantine's whisky - as well as snack food chains such as Dunkin' Donuts and Baskin-Robbins ice cream. The WSJ said that the two were ripe for consolidation, having each dealt with problematic parts of their portfolio. Pernod has reduced the debt it took on to fund the Seagram purchase to just 1.8bn euros, while Allied has improved the performance of its fast-food chains.
## 6 Japan narrowly escapes recession\n\nJapan's economy teetered on the brink of a technical recession in the three months to September, figures show.\n\nRevised figures indicated growth of just 0.1% - and a similar-sized contraction in the previous quarter. On an annual basis, the data suggests annual growth of just 0.2%, suggesting a much more hesitant recovery than had previously been thought. A common technical definition of a recession is two successive quarters of negative growth.\n\nThe government was keen to play down the worrying implications of the data. "I maintain the view that Japan's economy remains in a minor adjustment phase in an upward climb, and we will monitor developments carefully," said economy minister Heizo Takenaka. But in the face of the strengthening yen making exports less competitive and indications of weakening economic conditions ahead, observers were less sanguine. "It's painting a picture of a recovery... much patchier than previously thought," said Paul Sheard, economist at Lehman Brothers in Tokyo. Improvements in the job market apparently have yet to feed through to domestic demand, with private consumption up just 0.2% in the third quarter.
## Category Complete_Filename
## 1 business 001.txt-business
## 2 business 002.txt-business
## 3 business 003.txt-business
## 4 business 004.txt-business
## 5 business 005.txt-business
## 6 business 006.txt-business2. Find out about the name of the categories and the number of observations in each of them.
# list of the categories in the data set
unique(df_final$Category)
## [1] "business" "entertainment" "politics" "sport"
## [5] "tech"
table(df_final$Category)
##
## business entertainment politics sport tech
## 510 386 417 511 4013. Convert the data set into a document-term matrix and use the findFreqTerms function to keep the terms which their frequency is higher than 10. It is also a good idea to apply some text preprocessing before this conversion: e.g., remove non-UTF-8 characters, convert the words into lowercase, remove punctuation, numbers, stopwords, and whitespaces.
## set the seed to make your partition reproducible
set.seed(123)
docs <- Corpus(VectorSource(df_final$Content))
# we can create the dtm matrix in on-go or with separate functions as below
# dtm <- DocumentTermMatrix(docs,
# control = list(tolower = TRUE,
# removeNumbers = TRUE,
# removePunctuation = TRUE,
# stopwords = TRUE
# ))
# remove non-UTF-8 characters
docs <- tm_map(docs, iconv, from = "UTF-8", to = "UTF-8", sub = '')
# standardize to lowercase
docs <- tm_map(docs, content_transformer(tolower))
# remove tm stopwords
docs <- tm_map(docs, removeWords, stopwords())
# standardize whitespaces
docs <- tm_map(docs, stripWhitespace)
# remove punctuation
docs <- tm_map(docs, removePunctuation)
# remove numbers
docs <- tm_map(docs, removeNumbers)
dtm <- DocumentTermMatrix(docs)
# words appearing more than 10x
features <- findFreqTerms(dtm, 10)
head(features)
## [1] "accounts" "advert" "advertising" "alexander" "already"
## [6] "also"4. Partition the original data into training and test sets with 80% for training and 20% for test.
## 75% of the sample size
smp_size <- floor(0.80 * nrow(df_final))
set.seed(123)
train_idx <- sample(seq_len(nrow(df_final)), size = smp_size)
# set for the original raw data
train1 <- df_final[train_idx,]
test1 <- df_final[-train_idx,]
# set for the cleaned-up data
train2 <- docs[train_idx]
test2 <- docs[-train_idx]5. Create separate document-term matrices for the training and the test sets using the previous frequent terms as the input dictionary and convert them into data frames.
dtm_train <- DocumentTermMatrix(train2, list(dictionary = features))
dtm_test <- DocumentTermMatrix(test2, list(dictionary = features))
dtm_train <- as.data.frame(as.matrix(dtm_train))
dtm_test <- as.data.frame(as.matrix(dtm_test))6. OPTIONAL: Use the cbind function to add the categories to the train_dtm data and name the column y.
dtm_train <- cbind(cat = factor(train1$Category), dtm_train)
dtm_test <- cbind(cat = factor(test1$Category), dtm_test)
dtm_train <- as.data.frame(dtm_train)
dtm_test <- as.data.frame(dtm_test)7. OPTIONAL: Fit a SVM model with a linear kernel on the training data set. Predict the categories for the training and test data.
fit_svm <- svm(cat ~ ., data = dtm_train)
## Warning in svm.default(x, y, scale = scale, ..., na.action = na.action):
## Variable(s) 'nestle' and 'bravery' and 'duran' and 'baros' and 'espn' constant.
## Cannot scale data.
summary(fit_svm)
##
## Call:
## svm(formula = cat ~ ., data = dtm_train)
##
##
## Parameters:
## SVM-Type: C-classification
## SVM-Kernel: radial
## cost: 1
##
## Number of Support Vectors: 1488
##
## ( 292 358 247 259 332 )
##
##
## Number of Classes: 5
##
## Levels:
## business entertainment politics sport tech
# prediction on training data
pred_svm_train <- predict(fit_svm, dtm_train)
fit_svm_table <- table(dtm_train$cat, pred_svm_train, dnn = c("Actual", "Predicted"))
fit_svm_table
## Predicted
## Actual business entertainment politics sport tech
## business 406 0 1 1 1
## entertainment 12 273 2 28 3
## politics 27 0 282 27 1
## sport 0 0 0 396 0
## tech 24 4 0 14 278
# prediction on test data
pred_svm_test <- predict(fit_svm, dtm_test)
fit_svm_test <- table(dtm_test$cat, pred_svm_test, dnn = c("Actual", "Predicted"))
fit_svm_test
## Predicted
## Actual business entertainment politics sport tech
## business 100 0 1 0 0
## entertainment 5 58 0 5 0
## politics 7 0 64 9 0
## sport 0 0 0 114 1
## tech 10 4 0 6 61
# You can use this table to calculate Accuracy, Sensitivity, Specificity, Pos Pred Value, and Neg Pred Value. There are also many functions available for this purpose, for example the `confusionMatrix` function from the `caret` package.Latent Dirichlet allocation (LDA) is a particularly popular method for fitting a topic model. It treats each document as a mixture of topics, and each topic as a mixture of words. This allows documents to “overlap” each other in terms of content, rather than being separated into discrete groups, in a way that mirrors typical use of natural language.
8. Use the LDA function from the topicmodels package to train an LDA model with 5 topics with the Gibbs sampling method.
# An LDA topic model with 5 topics; if it takes a lot of time for you run the code with k = 2
out_lda <- LDA(dtm, k = 5, method= "Gibbs", control = list(seed = 321))
out_lda
## A LDA_Gibbs topic model with 5 topics.
# Sometimes you can decide to use the removeSparseTerms function to remove sparse terms from a document-term or term-document matrix. This will speed up the process of topic modeling while loses some information.
# dtm_cut <- removeSparseTerms(dtm, sparse = 0.93)9. The tidy() method is originally from the broom package (Robinson 2017), for tidying model objects. The tidytext package provides this method for extracting the per-topic-per-word probabilities, called “beta”, from the LDA model. Use this function and check the beta probabilites for each term and topic.
lda_topics <- tidy(out_lda, matrix = "beta")
lda_topics
## # A tibble: 154,280 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 accounts 0.000919
## 2 2 accounts 0.00000106
## 3 3 accounts 0.000103
## 4 4 accounts 0.00000126
## 5 5 accounts 0.000000907
## 6 1 adjust 0.0000532
## 7 2 adjust 0.00000106
## 8 3 adjust 0.000000924
## 9 4 adjust 0.00000126
## 10 5 adjust 0.000000907
## # ℹ 154,270 more rows10. Use the code below to plot the top 20 terms within each topic.
lda_top_terms <- lda_topics %>%
group_by(topic) %>%
slice_max(beta, n = 20) %>% # We use dplyr’s slice_max() to find the top 10 terms within each topic.
ungroup() %>%
arrange(topic, -beta)
lda_top_terms %>%
mutate(term = reorder_within(term, beta, topic)) %>%
ggplot(aes(beta, term, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
scale_y_reordered()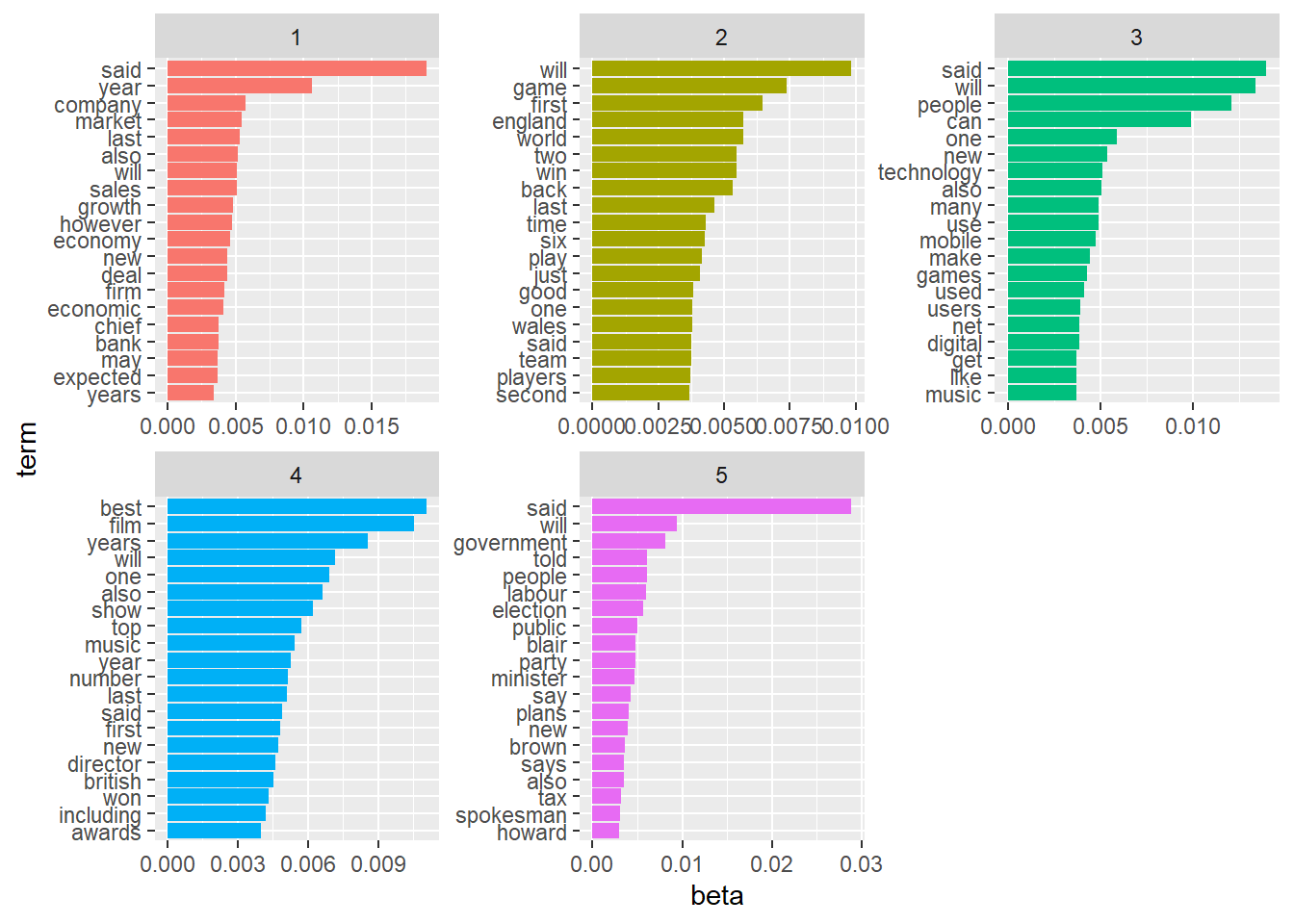
11. Use the code below to save the terms and topics in a wide format.
beta_wide <- lda_topics %>%
mutate(topic = paste0("topic", topic)) %>%
pivot_wider(names_from = topic, values_from = beta) %>%
mutate(log_ratio21 = log2(topic2 / topic1)) %>%
mutate(log_ratio31 = log2(topic3 / topic1))%>%
mutate(log_ratio41 = log2(topic4 / topic1))%>%
mutate(log_ratio51 = log2(topic5 / topic1))
beta_wide
## # A tibble: 30,856 × 10
## term topic1 topic2 topic3 topic4 topic5 log_ratio21 log_ratio31
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 accounts 9.19e-4 1.06e-6 1.03e-4 1.26e-6 9.07e-7 -9.76 -3.16
## 2 adjust 5.32e-5 1.06e-6 9.24e-7 1.26e-6 9.07e-7 -5.65 -5.85
## 3 advert 1.04e-6 1.06e-6 6.56e-5 7.71e-5 9.07e-7 0.0220 5.98
## 4 advertising 1.78e-4 1.06e-6 2.87e-4 1.26e-6 9.07e-7 -7.40 0.689
## 5 alexander 1.04e-6 1.06e-6 1.02e-5 3.93e-4 9.07e-7 0.0220 3.29
## 6 already 6.89e-4 3.61e-4 1.97e-3 5.57e-4 1.04e-3 -0.933 1.51
## 7 also 5.13e-3 2.19e-3 5.06e-3 6.64e-3 3.49e-3 -1.23 -0.0214
## 8 amount 6.27e-4 1.06e-6 5.56e-4 1.26e-6 3.72e-5 -9.21 -0.174
## 9 analysts 2.81e-3 1.06e-6 1.30e-4 1.26e-6 9.07e-7 -11.4 -4.43
## 10 aol 1.04e-6 1.06e-6 2.60e-4 1.26e-6 9.07e-7 0.0220 7.96
## # ℹ 30,846 more rows
## # ℹ 2 more variables: log_ratio41 <dbl>, log_ratio51 <dbl>12. Use the log ratios to visualize the words with the greatest differences between topic 1 and other topics. Below you see this analysis for topics 1 and 2.
# topic 1 versus topic 2
lda_top_terms1 <- beta_wide %>%
slice_max(log_ratio21, n = 10) %>%
arrange(term, -log_ratio21)
lda_top_terms2 <- beta_wide %>%
slice_max(-log_ratio21, n = 10) %>%
arrange(term, -log_ratio21)
lda_top_terms12 <- rbind(lda_top_terms1, lda_top_terms2)
# this is for ggplot to understand in which order to plot name on the x axis.
lda_top_terms12$term <- factor(lda_top_terms12$term, levels = lda_top_terms12$term[order(lda_top_terms12$log_ratio21)])
# Words with the greatest difference in beta between topic 2 and topic 1
lda_top_terms12 %>%
ggplot(aes(log_ratio21, term, fill = (log_ratio21 > 0))) +
geom_col(show.legend = FALSE) +
scale_y_reordered() +
theme_minimal()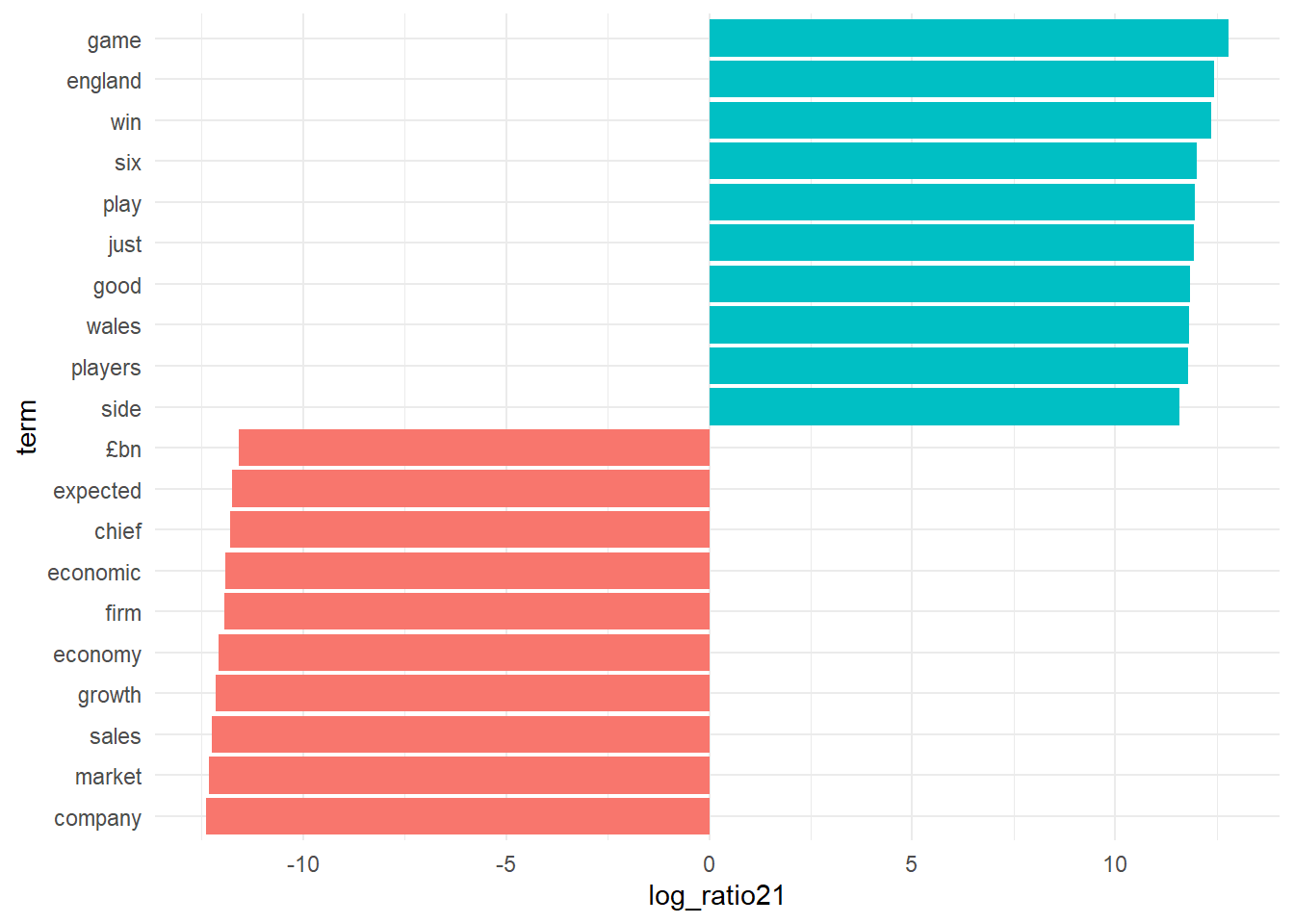
# topic 1 versus topic 3
lda_top_terms1 <- beta_wide %>%
slice_max(log_ratio31, n = 10) %>%
arrange(term, -log_ratio31)
lda_top_terms2 <- beta_wide %>%
slice_max(-log_ratio31, n = 10) %>%
arrange(term, -log_ratio31)
lda_top_terms13 <- rbind(lda_top_terms1, lda_top_terms2)
# this is for ggplot to understand in which order to plot name on the x axis.
lda_top_terms13$term <- factor(lda_top_terms13$term, levels = lda_top_terms13$term[order(lda_top_terms13$log_ratio31)])
# Words with the greatest difference in beta between topic 2 and topic 1
lda_top_terms13 %>%
ggplot(aes(log_ratio31, term, fill = (log_ratio31 > 0))) +
geom_col(show.legend = FALSE) +
scale_y_reordered() +
theme_minimal()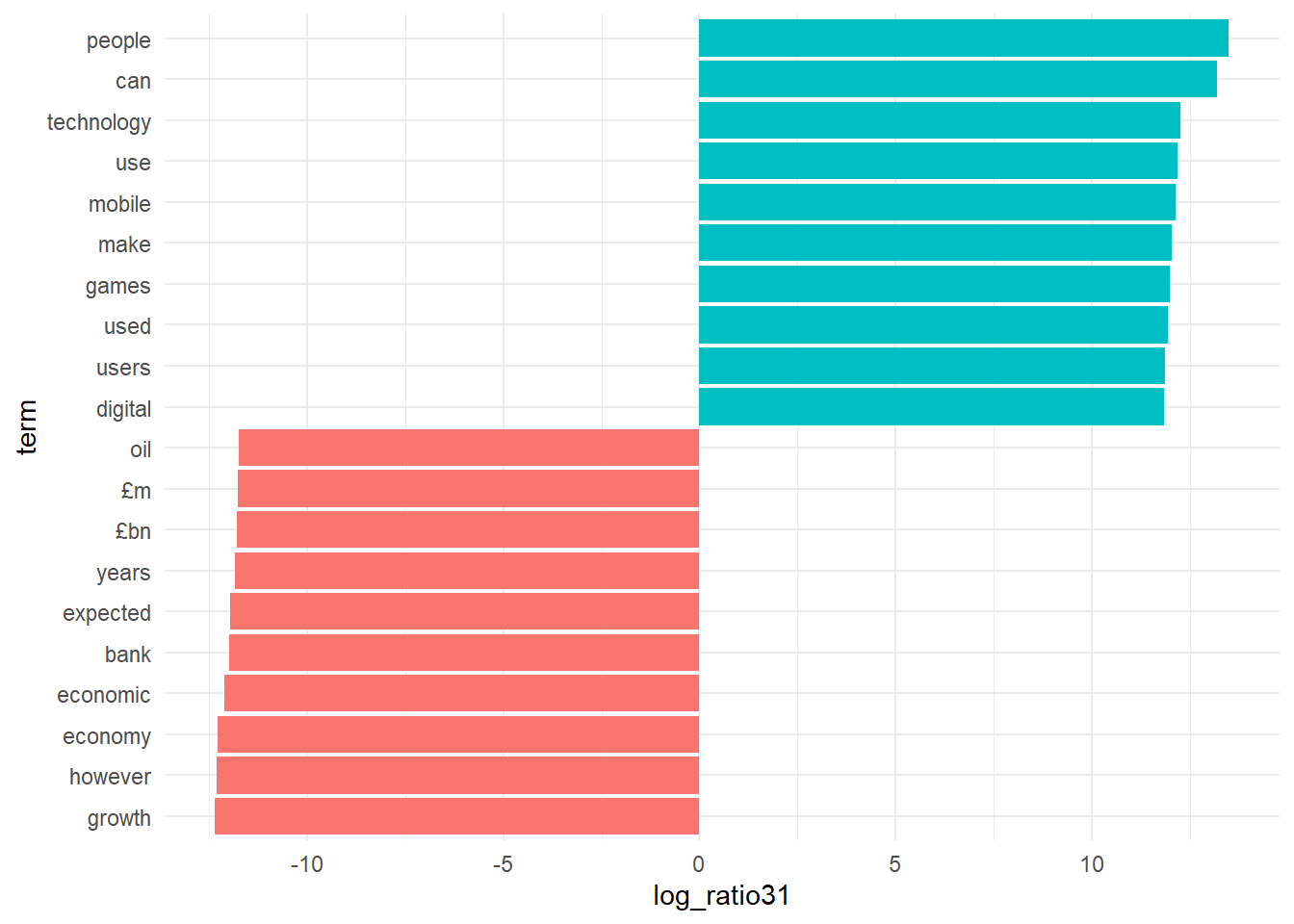
# topic 1 versus topic 4
lda_top_terms1 <- beta_wide %>%
slice_max(log_ratio41, n = 10) %>%
arrange(term, -log_ratio41)
lda_top_terms2 <- beta_wide %>%
slice_max(-log_ratio41, n = 10) %>%
arrange(term, -log_ratio41)
lda_top_terms14 <- rbind(lda_top_terms1, lda_top_terms2)
lda_top_terms14[1,]$term <- 'SPELLING ERROR!'
# this is for ggplot to understand in which order to plot name on the x axis.
lda_top_terms14$term <- factor(lda_top_terms14$term, levels = lda_top_terms14$term[order(lda_top_terms14$log_ratio41)])
# Words with the greatest difference in beta between topic 2 and topic 1
lda_top_terms14 %>%
ggplot(aes(log_ratio41, term, fill = (log_ratio41 > 0))) +
geom_col(show.legend = FALSE) +
scale_y_reordered() +
theme_minimal()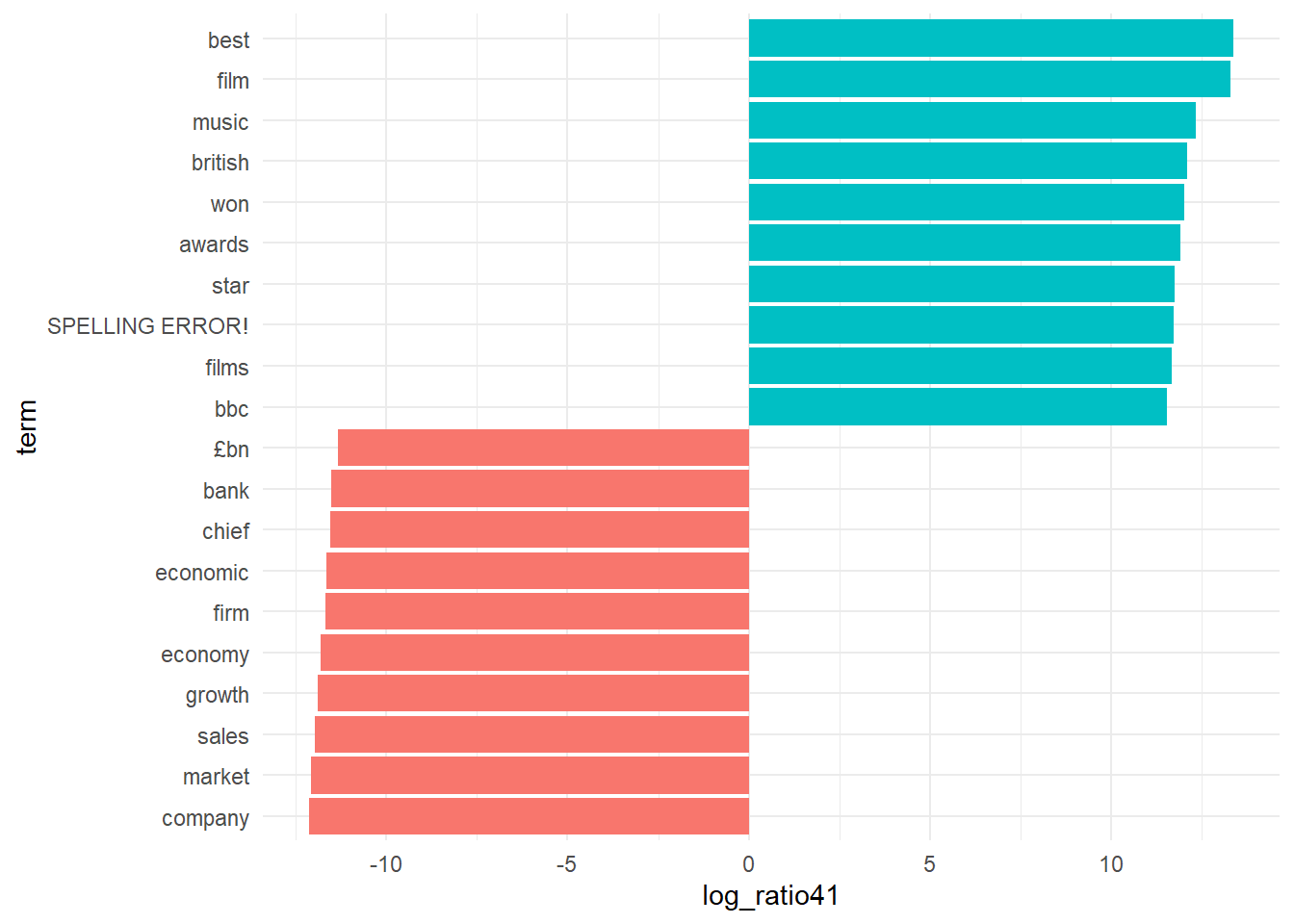
# topic 1 versus topic 5
lda_top_terms1 <- beta_wide %>%
slice_max(log_ratio51, n = 10) %>%
arrange(term, -log_ratio51)
lda_top_terms2 <- beta_wide %>%
slice_max(-log_ratio51, n = 10) %>%
arrange(term, -log_ratio51)
lda_top_terms15 <- rbind(lda_top_terms1, lda_top_terms2)
# this is for ggplot to understand in which order to plot name on the x axis.
lda_top_terms15$term <- factor(lda_top_terms15$term, levels = lda_top_terms15$term[order(lda_top_terms15$log_ratio51)])
# Words with the greatest difference in beta between topic 2 and topic 1
lda_top_terms15 %>%
ggplot(aes(log_ratio51, term, fill = (log_ratio51 > 0))) +
geom_col(show.legend = FALSE) +
scale_y_reordered() +
theme_minimal()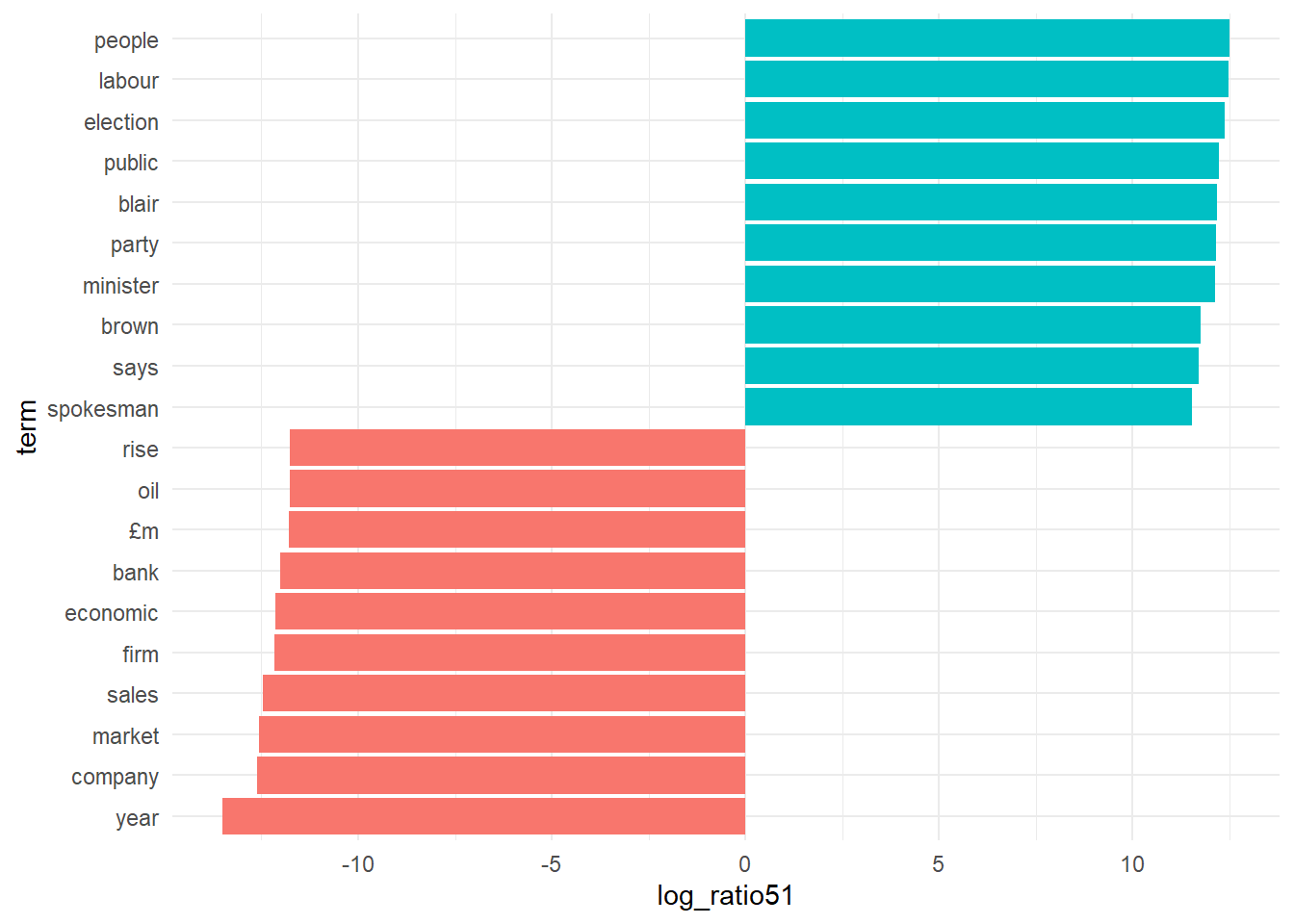
13. Besides estimating each topic as a mixture of words, LDA also models each document as a mixture of topics. We can examine the per-document-per-topic probabilities, called “gamma”, with the matrix = "gamma" argument in the tidy() function. Call this function for your LDA model and save the probabilities in a varibale named lda_documents.
lda_documents <- tidy(out_lda, matrix = "gamma")14. Check the topic probabilities for documents with the index number of 1, 1000, 2000, 2225.
lda_documents[lda_documents$document == 1,]
## # A tibble: 5 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 1 1 0.556
## 2 1 2 0.0490
## 3 1 3 0.203
## 4 1 4 0.133
## 5 1 5 0.0594
lda_documents[lda_documents$document == 1000,]
## # A tibble: 5 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 1000 1 0.0658
## 2 1000 2 0.107
## 3 1000 3 0.0784
## 4 1000 4 0.376
## 5 1000 5 0.373
lda_documents[lda_documents$document == 2000,]
## # A tibble: 5 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 2000 1 0.161
## 2 2000 2 0.0968
## 3 2000 3 0.286
## 4 2000 4 0.198
## 5 2000 5 0.258
lda_documents[lda_documents$document == 2225,]
## # A tibble: 5 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 2225 1 0.0300
## 2 2225 2 0.186
## 3 2225 3 0.522
## 4 2225 4 0.164
## 5 2225 5 0.0985
tidy(dtm) %>%
filter(document == 2225) %>%
arrange(desc(count))
## # A tibble: 766 × 3
## document term count
## <chr> <chr> <dbl>
## 1 2225 gaming 23
## 2 2225 game 22
## 3 2225 games 22
## 4 2225 online 22
## 5 2225 playing 20
## 6 2225 time 20
## 7 2225 hours 19
## 8 2225 can 15
## 9 2225 people 15
## 10 2225 play 15
## # ℹ 756 more rows
# df_final[2225,]$Content15. Use the code below to visualise the topic probabilities for the example documents in question 14.
# reorder titles in order of topic 1, topic 2, etc before plotting
lda_documents[lda_documents$document %in% c(1, 1000, 2000, 2225),] %>%
mutate(document = reorder(document, gamma * topic)) %>%
ggplot(aes(factor(topic), gamma)) +
geom_boxplot() +
facet_wrap(~ document) +
labs(x = "topic", y = expression(gamma)) +
theme_minimal()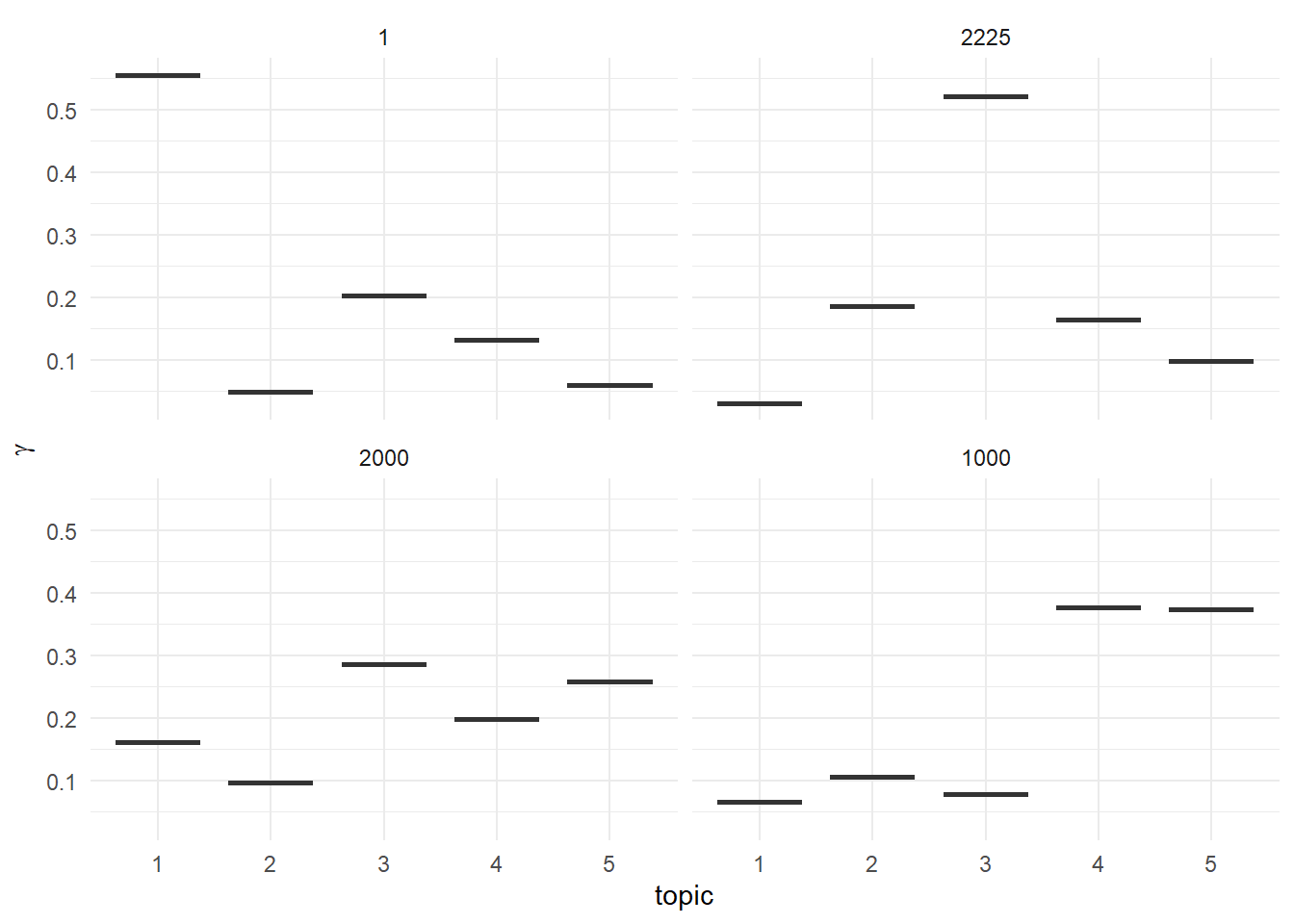
The LDA() function in the topicmodels package is only one implementation of the latent Dirichlet allocation algorithm. For example, the mallet package (Mimno 2013) implements a wrapper around the MALLET Java package for text classification tools, and the tidytext package provides tidiers for this model output as well. The textmineR package has extensive functionality for topic modeling. You can fit Latent Dirichlet Allocation (LDA), Correlated Topic Models (CTM), and Latent Semantic Analysis (LSA) from within textmineR (https://cran.r-project.org/web/packages/textmineR/vignettes/c_topic_modeling.html).